在阅读目标检测相关的论文中遇到评估模型性能时使用mAP这一概念,为此查阅相关资料来进行理解。此外,还有
平均精度(AP)、查准率(precision)、查全率(recall)、IOU、置信度阈值(confidence thresholds)
等概念。
1.查准率(precision)和查全率(recall)
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,令TP、FP、TN、FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数。分类结果的“混淆矩阵”(confusion matrix)如表所示:
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率P和查全率R分别定义为:
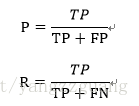
一个例子为:P=“挑出来的西瓜中有多少比例是好瓜”,R=“所有好瓜中有多少比例被挑出来”。查全率和查准率是一对矛盾的度量。一般来说查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
参考资料:《机器学习》 周志华,清华大学出版社
2.平均精度(AP)和平均精度均值(mAP)
Mean Average Precision(mAP)通常在信息检索和目标检测中作为评估标准使用。在这两个领域中mAP的计算方法不同,这里主要介绍目标检测中的mAP。目标检测中定义的mAP最先在PASCAL VisualObjects Classes(VOC) challenge中使用,可以参考相关论文。
至少有两个变量用来决定precison和recall,分别是IOU和置信度阈值(confidencethresholds)。IOU是一个简单的几何度量,可以容易地被标准化,例如PASCAL VOC以50% IOU来计算mAP,COCO中更进一步地在范围5%-95%中计算mAP。另一方面置信度也影响模型,例如一个以50%置信度设计的模型可能等于别的以80%置信度设计的模型,这改变了precison recall曲线形状。因此PASCAL VOC组织提出了一种方法来解释这个变化。
我们需要以模型不可知的方式来作为评估模型的标准。论文中提出一种称为Average Precision(AP)的方法来计算。对给定的任务和类别,precision/recall曲线以一种方法的排序输出来计算。Recall被定义为给定序列上所有正样本的部分;precison被定义为正类别序列上的所有样本。AP概括了precision/recall曲线的形状,被定义为在一组11个等间距recall水平\[0, 0.1, 0.2,…,1\]上的precision平均值。这意味着我们选择11个不同的置信度阈值(这决定序列)。置信度阈值的设定需要使recall值为0,0.1,0.2,…,1。这使得mAP可以纵览整个precison/recall曲线。mAP就是所有AP值的平均值。
下面是几个在比较mAP值时需要记住的几个重点:
(1)mAP需要计算完整个数据集;
(2)虽然模型输出的绝对量化是难以解释的,但mAP可以通过一个很好的相关性标准来帮助我们。当我们在流行的公开数据集上计算这个标准时,它可以很容易地用来比较目标检测的新旧方法。
(3)根据类别在训练集上的分布方式,AP值可能在某些类别上从很高(这有很好的训练数据)变化到很低(对数据很少或不好的类别)。所以你的mAP可能是合适的,但你的模型可能对某些类别非常好而对某些类别非常差。因此当分析你的模型结果时,观察独立类别的AP是明智的。这些值可能作为添加更多训练样本的指示器。